Jet.Net Status Page Help
The Jet.Net Status Page gives you up-to-the-minute information about our network infrastructure. Every five minutes or so we scan our entire network and all upstream paths to the Internet, and compile a summary of that scan on this page. The summary starts off with a timestamp and a bulletin noting any known connectivity problems or outages. This is followed by status reports from each of our important infrastructure components, and bandwidth congestion measurements for each of our several paths to the Internet backbone.
Network Component Status
The critical components in our backbone network are the routers, Domain Name System servers, ISDN access servers, and RADIUS authentication servers. The status page reports the condition of each component as UP (green) or DOWN (red) along with the component name.


Routers carry traffic from dedicated Frame Relay and dial-up ISDN customers across our internal network and out to the appropriate Internet Backbone path for distribution to the Internet. If a router is down, then some part of Jet.Net's network infrastructure isn't working correctly. We may deliberately bring a router down to perform periodic maintenance or upgrades, but such outages are usually brief. The status message will detail the extent and expected duration of any outage if this is the case. If a router goes down inadvertantly, our 24-hour response team is notified automatically by page within a few minutes, and will immediately begin working on the problem.


Domain Name Servers, also called DSN servers, provide the name-to-IP-address and IP-Address-to-name translations required for you to access the Internet correctly. We have both local and remote backup name servers, which come into play automatically to take over should our primary name server fail. For this to work correctly, you should ensure that your own computers accessing the Internet through Jet.Net are configured with the proper primary and secondary DNS addresses. These addresses were given to you on your Jet.Net Customer Information sheet. Although redundant DNS servers automatically kick in when the primary server fails, we handle DNS outages with high priority, just like a router outage, to ensure continued reliable service.


ISDN access servers provide dial-up ISDN connectivity for both on-demand and dedicated Centrex ISDN customers. If an access server is down, then dial-up access through that Point of Presence (POP) may be constrained or disabled. When possible, we provide redundant access circuits and route calls around disabled lines to working circuits. This helps minimize connectivity problems due to access server loss. The increased load on remaining servers may result in connectivity delays for on-demand ISDN customers. As with routers, if an access server goes down inadvertantly, our 24-hour response team is paged for immediate response.


RADIUS authentication servers provide high-speed password validation and accurate accounting for dial-up customers. Because ISDN connects in a couple of seconds or less, speedy authentication is essential. Thus we run our authentication servers on high-performance Silicon Graphics Indigo servers. Should the primary RADIUS server go down, the backup server automatically takes over authentication responsibilites until the primary server is restored by our 24-hour on-call technicians.
Upstream Path Performance
The status page reports the relative throughput of each upstream connection path using a bargraph display. An all-green bar for a path indicates that no congestion was encountered in the last scan. Varying degrees of congestion are indicated by increasingly-yellow bars. A path that is completely blocked shows as a red DOWN indication; you can usually see the increased load on remaining paths as they take up the traffic originally carried by the downed path.




Jet.Net's upstream Internet connection, carried by the Los Nettos Internet consortium, currently provides four different, redundant, paths to the Internet backbone: MCI, ISI (a service of the University of Southern California), the Jet Propulsion Laboratory (JPL), and Genuity Internet. Normally traffic volume is distributed across all four connections, so depending on your destination, your packets could take any of the four paths, although the heaviest load is carried to MCI's 600-Mbps ATM backbone. Should any of the upstream paths fail, the Los Nettos core routers automatically redirect traffic along the remaining paths to provide continued connectivity. Usually this increases the traffic load on the operating paths, which can result in network slowdowns.

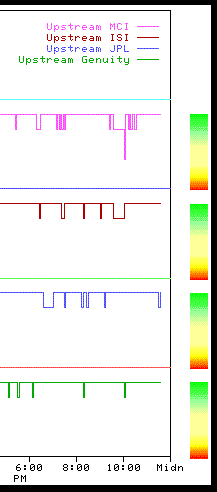
Status History
Press the Status History button to view a graphical "weather report" of upstream connectivity history. Be sure your browser window is wide enough to display both the graph and the right-side "rain gauge" (or "rainbow") side-by-side (if your browser window is too narrow, the rain guage will appear below the graph). These graphs are designed to both give you an intuitive feel for the upstream Internet performance, and to help you track partial network outages or network congestion occuring outside our metropolitan network.
The graph shows separate colored plots for each upstream connectivity route, over a 24-hour period. There are five levels of accessibility measured; the rain guage on the right side of each plot depicts normal, congested, and blocked accessibility.. The top (green) range represents optimal performance; moving down through the middle (yellow) range are increasing amounts of congestion; the bottom (red) range indicates severe congestion or loss of connectivity. Separate graphs appear for today and yesterday; prior graphs are kept on file and available on request.
Dips within the green range are perfectly acceptable, and quite common; they represent the normal flow of Internet traffic across the backbone.
Periodic, brief drops into the middle of the yellow range will occur regularly. Internet traffic tends to be bursty, with random accumulations of traffic causing brief periods of slow performance. Infrequent bursts are imperceptible to most users.
Brief excursions into the bottom yellow range indicate heavy traffic loads, but unless such loads persist for many minutes, usually won't be noticable. A long period of heavy load may indicate that traffic from elsewhere on the Internet is being rerouted over that connection to accomodate an outage in another backbone pathway. This rerouting causes congestion until the problem pathway is restored.
Measurements in the red range show severe congestion, or a possible outage. Any red-range measurement persisting for more than five minutes is classified by our automated network monitor as an outage, and a technician is paged to investigate. In the meantime, if alternative backbone pathways are available (and they often are), the upstream routers will automatically reroute traffic over an alternative path. As noted above, this may result in congestion on otherwise functioning paths.
How to Track Down Internet Blockages
When you can't get to a particular Internet site today, but could yesterday, you're often tempted to ask "What's wrong with Jet.Net?" Probably nothing is wrong with Jet.Net, but something may be wrong with the Internet at large. If Jet.Net's infrastucture shows no problems, and the upstream paths are not congested, then you may be seeing an Internet blockage somewhere "out there" on the 'Net. We provide you with tools to help you diagnose such problems, and to report them to us if you feel they require our attention.
Although the Internet is robust and fairly reliable, it is never completely operational everywhere at one time. An individual destination site may be "off the air" for maintenance, or may be inaccessible because of some intermediate routing problem on the Internet backbone. There is usually nothing we can do at Jet.Net about such situations; that's simply how the Internet works. However, if you repeatedly have problems reaching a site that you feel should be readily accessible, you can run a traceroute to the destination to see where the blockage is. Just click the Traceroute button at the bottom of the Status page:

Then enter the name of the site you want to trace (e.g., www.sysci.org). Do not enter the "html://" prefix. A typical traceroute looks something like this:
Traceroute
To www.sysci.org from www.jet.net:
traceroute to www.sysci.org (205.227.180.10), 30 hops max, 40 byte packets
1 router1.jet.net (204.140.245.1) 2 ms 2 ms 2 ms
2 t1-router0.jet.net (208.0.21.1) 4 ms 4 ms 4 ms
3 204.74.127.250 (204.74.127.250) 6 ms 4 ms 4 ms
4 jpl-acg.ln.net (130.152.120.1) 6 ms 6 ms 6 ms
5 cit-jpl.ln.net (130.152.152.1) 9 ms 7 ms 6 ms
6 usc-cit.ln.net (130.152.88.1) 9 ms 9 ms 8 ms
7 SWRL-USC-GW.LN.NET (204.102.78.34) 8 ms 8 ms (ttl=251!) 7 ms
8 border1-hssi1-0.Bloomington.mci.net (204.70.48.5) 12 ms 12 ms 12 ms
9 core1-fddi-0.Bloomington.mci.net (204.70.2.129) 147 ms 150 ms 220 ms
10 166.48.19.250 (166.48.19.250) 25 ms 46 ms 26 ms
11 166.48.19.250 (166.48.19.250) 24 ms 23 ms 25 ms
12 paloalto-cr9.bbnplanet.net (131.119.0.209) 23 ms 24 ms 23 ms
13 sysci.bbnplanet.net (131.119.26.90) 31 ms 31 ms 31 ms
14 iris0.sysci.org (205.227.180.10) 31 ms 31 ms 30 ms
Each numbered line on the traceroute output represents one "hop" to a router on the route between Jet.Net and your destination. Each line lists the Internet name and IP address of the router for that hop, followed by the round trip time of the packets to that router. The names sometimes give you some idea of the geography of the path, although they often are just cryptic titles. Each hop has three round trip times, measured in milliseconds, to give you an idea of the average packet travel time to that point.
If any particular hop has much higher round trip times than other hops, then that router is experiencing congestion. If a router is down completely, you'll see either a series of asterisks, or an H! indicating the host you specified is unreachable beyond that point:
Traceroute
To www.sysci.org from www.jet.net:
traceroute to www.sysci.org (205.227.180.10), 30 hops max, 40 byte packets
1 router1.jet.net (204.140.245.1) 2 ms 2 ms 2 ms
2 t1-router0.jet.net (208.0.21.1) 4 ms 4 ms 4 ms
3 204.74.127.250 (204.74.127.250) 6 ms 4 ms 4 ms
4 jpl-acg.ln.net (130.152.120.1) 6 ms 6 ms 6 ms
5 cit-jpl.ln.net (130.152.152.1) 9 ms 7 ms 6 ms
6 usc-cit.ln.net (130.152.88.1) 9 ms 9 ms 8 ms
7 SWRL-USC-GW.LN.NET (204.102.78.34) 8 ms 8 ms (ttl=251!) 7 ms
8 border1-hssi1-0.Bloomington.mci.net (204.70.48.5) 12 ms 12 ms 12 ms
9 core1-fddi-0.Bloomington.mci.net (204.70.2.129) 147 ms 150 ms 220 ms
10 166.48.19.250 (166.48.19.250) 25 ms 46 ms 26 ms
11 166.48.19.250 (166.48.19.250) 24 ms 23 ms 25 ms
12 paloalto-cr9.bbnplanet.net (131.119.0.209) * * H!
If you encounter this situation, then you've located a failed node on the Internet. Since most of the Internet backbone is continuously monitored, chances are that the people responsible for the downed router know about the problem and are working on it. There is nothing you as an Internet end user can do to solve the problem. However, if a route is chronically down, or you detect a failure in either the Jet.Net or Los Nettos infrastructure, feel free to submit a problem report by pressing the SUBMIT PROBLEM REPORT button on the Status page. We can't always respond to these reports, particularly if the outage is not anything we can affect, but we investigate every one. Be sure to copy and paste into your problem report a sample traceroute illustrating the problem you're reporting!